Methods In Programming
I finally got around to reading "The C Programming Language" (2nd Edition). It's a book that I've heard recommended many times. I think most often people recommend it as an introduction to C, which is exactly what it is. I am not someone who needs another introduction to C in my life, but I am quite interested in how programming books are written. What's the style of the writing? What's the ratio of examples to explanations? What sort of information is it actually trying to convey? I wanted to have a look.
I don't have anything to say about it on those questions though. I'm still thinking about those questions and exploring them, I have a long way to go in forming opinions about them. I want to focus on some specific ideas in the book about *how* to program. Things you might call "methodology" information. Information that sounds like "When you have a problem, first what you do is ..., second what you do is ..." etc.
Figuring out good methodology is hard but important work. It's hard because there is no formula for correct or incorrect methodology. It's a game of comparison. "Does this method work better than that method?"
It's also hard because each person has to plug their own values into the problem. I can explain how one methodology is better than another according to what I value but I also want to leave you with the tools to plug in your values and make that determination for yourself. I could also try to persuade you to modify your values, but that's a different sort of conversation for another time.
A third reason why methodology discussions are so hard is that methods are so difficult to measure. It takes a long time to apply a particular method to a problem and fairly assess the results. I can support a thesis with arguments and anecdotes, but I fully recognize that I don't have the kind of data I would want to have to really back up my claims here.
Despite all the difficulties I believe it is worthwhile to press on and have this discussion. Because I believe that, even in the absence of hard data to decide difficult questions, being aware of the questions can help us understand what we are doing.
"Easier to Read"
The first moment where I took issue with the book is admittedly quite minor. I think this example more-so shows the age of the book than anything else. I suspect this is a bit of stylistic advice that has fallen largely out of fashion. I'm including it because it lets me setup a simple template for how the rest of the critique will work.
In the first chapter the book is giving a tutorial to the absolute basics of the language. In section 1.5.1 it is covering how to copy a file with a few standard library functions. It gives the snippet:
#include <stdio.h>
/* copy input to output; 1st version */
main()
{
int c;
c = getchar();
while (c != EOF) {
putchar(c);
c = getchar();
}
}
It's main focus is on explaining getchar, putchar, and EOF. Then it turns to another point saying "The program for copying would be written more concisely by experienced C programmers." and providing an explanation for how this slightly different snippet works
#include <stdio.h>
/* copy input to output; 2nd version */
main()
{
int c;
while ((c = getchar()) != EOF) {
putchar(c);
}
}It gives a few reasons why an "experienced C programmer" would supposedly do this. One "This version centralized the input". Two "The resulting program is more compact". Three "once the idiom is mastered, [the program] is easier to read".
This passage in the book is not an explicit statement of methodology, it's actually just a lot closer to an explicit statement of values. The values expressed here are one "duplication of a key concept is bad", two "fewer instructions in the final program is good", three "code that is easier to read for experienced programmers is good". In cases to come we will have to "extract" the values being suggested, in this case though we have to "extract" the methodology. If any methodology is being implied by this passage it's something like "a programmer should modify code to have these given characteristics".
Next what I want to do is suggest some modifications to the values and see how the code works out under thos modifications. The new values will be more inline with what I personally value. As I said, I'm not making the argument for why these are better things to value in this post, I'm just showing how plugging in different values leads to different results.
First I am going to cross out this value: "code that is easier to read for experienced programmers is good"
And replace it with this: "code that is easier to read for inexperienced programmers is good"
As the book itself states - an idiom like while ((c = getchar()) != EOF) is easier to read once the idiom is mastered. Therefore the first snippet is easier to read for an inexperienced programmer than the second snippet. But we don't want to give up on the other two values, which I haven't modified.
Next I will add a second value: "spreading logic into multiple lines in the source code is good"
Importantly, this is not the opposite of the value "fewer instructions in the final program is good". That is about the total amount of output code, after the compiler has worked on it. Spreading out instructions in the source code does not necessarily mean increasing the amount of output code.
So the values I am looking at here are: One "duplication of a key concept is bad". Two "fewer instructions in the final program is good". Three "code that is easier to read for inexperienced programmers is good". Four "spreading logic into multiple lines in the source code is good".
I can plug these exact values into the rather generic methodology "a programmer should modify code to have these given characteristics" and then applying this method to the code snippet from this example I would get:
#include <stdio.h>
/* copy input to output; Allen's version */
main()
{
int c;
while (1) {
c = getchar();
if (c == EOF) {
break;
}
putchar(c);
}
}To summarize the outline of my approach, first I am laying out what the book has to say. From that I am extracting a methodology and values. Then I am suggesting modifications to the methodology and values - without any justification beyond my own taste. Then showing what the code might look like by applying my suggested method. What I skipped in this template is also explaining how the new methodology priotizes the new values. The methodology in this example was generic that it didn't need any explanation. Moving forward the methods will be more specific and therefore analyzing them will be more useful.
Narrative Driven Programming
Now we are turning to the big issue with the method of programming taught in "The C Programming Language" that made me want to write up this post. I don't know if this method has a name out there, so I'll use the name narrative driven programming. In the wild I see methods that I would call narrative driven programming a lot, although they are not all exactly the same. As I go I will point out the primary reason why I call this narrative driven programming, so you will be able to recognize similar methods in play out in the wild. Hopefully by naming it and disecting it I will help you become more aware of when you're using this method, and by showing some alternatives I hope to equip you with new options for you to apply according to your own best judgement.
In section 1.9 "The C Programming Language" gives it's first example of a program that does some interesting amount of work. The goal for this program is to "read a set of text lines and print the longest".
First the book gives this outline:
while (there's another line)
if (it's longer than the previous longest)
save it
save its length
print longest lineThere's no pre-cursor building up to the outline, the impression is that this step follows naturally from the problem statement. One interpretation of the book might be that it is showing us the outline of the program after the program is already written, to help the reader understand the program. However the text that follows really clearly "points the arrow" the other way around, positioning the final program as a step after the outline. Exactly quoting what follows:
After reasoning through how to construct functions that will make the final program "divide nicely" in the same way as the outline, the program is given:
#include <stdio.h>
#define MAXLINE 1000
int getline(char line[], int maxline);
void copy(char to[], char from[]);
/* print longest input line */
main()
{
int len;
int max;
char line[MAXLINE];
char longest[MAXLINE];
max = 0;
while ((len = getline(line, MAXLINE)) > 0)
if (len > max) {
max = len;
copy(longest, line);
}
if (max > 0)
printf("%s", longest);
return 0;
}
/* getline: read a line into s, return length */
int getline(char s[], int lim)
{
int c, i;
for (i=0; i<lim-1 && (c=getchar())!=EOF && c!='\n'; ++i)
s[i] = c;
if (c == '\n') {
s[i] = c;
++i;
}
s[i] = '\0';
return i;
}
/* copy: copy 'from' into 'to'; assume to is big enough */
void copy(char to[], char from[])
{
int i;
i = 0;
while ((to[i] = from[i]) != '\0')
++i;
}
To summarize, this is a method that creates programs and designs functions. The method goes: First create an outline for a program that solves the problem. Second design functions with that can fit into the outline of the program. Third implement the functions and plug them into a concrete version of the outline in the main path.
This time we don't have exact statements of what the values being maximized are, but we can infer a few by asking ourselves this question: "What does this method do well?"
For one thing it only requires intuition to get started. That's how the first step works, the outline comes from whatever intuitively seems like an outline that solves the problem. This is where my name narrative driven programming comes from. It all starts from a story about how the problem will be solved.
If you want a final program that reads like a story, this method is strong at that as well. The final main path is literally just the original outline constructed from intuition rendered out as concrete code.
Another strength of this method is that it arrives quite quickly to a minimal working program from the original outline. There are not a lot of in-between steps. All of the effort put in is directed towards arriving at the specified goal from the starting point.
To summarize, the values I see being emphasized by this method are: One rely on intuition to get things done efficiently. Two create programs that read like intuitive stories. Three focus only on the concrete task before you.
There are also some weaknesses I can see. This method does nothing to correct course if the original intuition expressed in the outline is incorrect. To discover a flaw in the original narrative, a programmer would either have to successfuly realize the mistake by analyzing their intuition carefully, or debug each individual piece and then the whole to observe the flaw.
Another weakness to this method is that leaves you completely empty handed if you don't already have an intuition on how to make your program. The first step is only possible if you have an idea for the outline.
Finally there's nothing about this method that makes it more likely to lead to functions that are easy to implement, or reusable. A slight change in the initial problem, or even a slight change in the initial outline can lead to wildly different function designs. For example, take a look at my outline for solving our current example problem.
split text into lines
for (each line)
if (this line is longer than the previous longest)
save it
print longest line
The functions implied by this outline are quite different! First it'll need a function that creates an array or list of strings to represent the lines. Then it'll avoid copying lines later because it can just save a reference to the longest line during the loop part. So the functional decomposition here is totally different.
If a small tweak in the initial problem or intuition leads to such drastically different functional decomposition, then applying this method exclusively over a long period of time would lead to rewriting a lot of code.
Some Corrective Methods
I don't know any programmers who are so rigid in their process that they literally only apply one method. There are some very easy ways to address the above weaknesses without having to overhaul the narrative driven method entirely.
For example, if you're stuck by the second weakness I pointed out, where you don't already have an intuition about where to get started. You can instead get a starting point by copying an already existing solution - provided you're copying something you have permission to copy of course.
When you copy something, it doesn't have to be a perfect fit for your problem, but instead of a method for converting an intuitive outline into code, you'll need a method for refining existing code to make it more appropriate for it's intended purpose. One such code refinement methodoly is Casey Muratori's semantic compression. Of course this is limited to what is available to you to copy.
There's also an easy way to address the third weakness, where the narrative driven methodology doesn't necessarily produce functions that will be easy to reuse in the future. The idea is to choose functions that are more basic than the alternatives. What you do is generate lots of initial intuitive outlines for a single problem, or set of related problems. This generates lots of different implied functions. If you then sort through these to find which ones work well as the basis for the others, your designs will be invalidated by changes in the initial setup less often.
To do this you have to have some way to compare two designs. A useful criteria for comparing functional designs can be found in Casey Muratori's talk designing and evaluating reusable components. It's not a talk on method as much as it is a talk on values, so if you've got your own idea of how to compare designs, you can just plug that in. So long as your criteria for comparison are consistent, you will at least reduce the fluctuations in your designs.
This method is also limitted by your ability to generate qualitatively different narratives for a given problem space, and it can be quite time intensive. While doing this is better for design than just the plain narrative driven method, I think we can have even more efficient methods if we're willing to step away from narrative driven programming all together.
Information Flow Programming
Here I'm going to describe a completely different method for getting from scratch to a working program. I'll call this method information flow programming. I've given this method a new name, but I want to point out some related concepts that have taught me to program this way.
One is Mike Acton's data oriented design. The reason I am not just reusing that name is that data oriented design puts a heavy emphasis on low level details. Cache coherence, branch prediction, tight instruction sequences in hot paths, things like that. All of that is very valuable in it's place, but the method I will detail in a minute will focus more on the "top half" of the design problem than the "bottom half".
Another related concept is functional programming, especially strongly typed functional programming like Haskell, and category theory. But these aren't really methods. They're more like systems of thinking about types and data transforms. If data oriented design is too "bottom heavy" then these are too "top heavy". They focus heavily on how computations can compose at a conceptual level, but I need something more practical for actually writing programs.
A third inspiring concept comes from Fabian Giesen's whirlwind introduction to dataflow graphs. The content of this post is very low level, at about the same level as the data oriented design talks, although in a different way. Near the end of that post Fabian says "Even though I’ve been talking about adding cycle estimates for compute-bound loops here, this technique works and is useful at pretty much any scale". The method I want to outline is very related to the technique in that post, but that post doesn't give it a name! Or maybe the name it gives is "dataflow graphs" but that doesn't sound like a method. I'm also going to tweak one thing. I won't bother with actually assigning costs to each computation in my design. I think the key idea is understanding the dependencies between each piece of information. Once we develop that habit, plugging in cost estimates is the easy part.
Here is a sketch of the "information flow" method.
First you identify each piece of information that is specified as input and output in the problem. Draw the following diagram for your program:

Second you identify ways you could break up the arrow into multiple arrows. You do this by inserting new intermediate information between the original input and output. Draw these diagrams as you think of them:
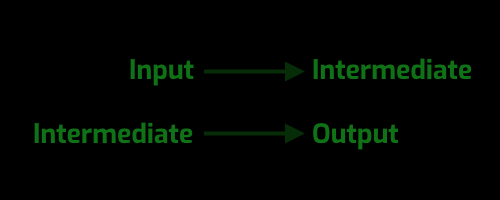
Third you determine which design of the ones you have generated has the properties that you need. This may include things like "maximal reuse of existing arrows", "minimizes the total cost of the longest path from input to output" (this requires you start estimating costs which I've left out here), "isolates the more unreliable paths", or "isolates dependencies on third party code". The more you use this method the more things you can "see" in the information flow diagram.
Four using the diagram of the chosen design, go and implement your system. Each arrow becomes a function or code path of some kind. Each "pole" or "label" is a data type, file format, or information channel of some kind.
Let me demonstrate this in action on the example problem from "The C Programming Language" we looked at earlier. Step one, here's diagram corresponding to the program as a whole.
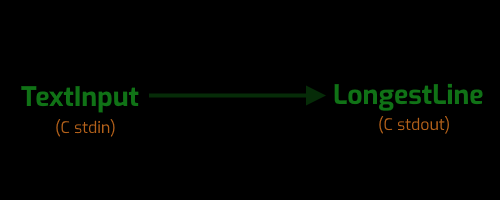
Notice that in addition to the type of input and type of output, I'm also including a notion of the meaning of the information, and the channel by which that information is being delivered. Capturing all of this in the diagram will help to make the final diagram a more complete representation of my design.
In step two I split the arrow up into "smaller" arrows. First I'll put in some arrows to get me out of the stdin channel into memory and later out of the memory channel to the stdout channel. When I am transfering channel-to-channel I generally try not to fuse it with an information transformation in my initial design. Fusing such things is for an optimization pass, but suched fused functions are less reusable and harder to implement correctly.
Then I introduce an "array of lines" intermediate to describe how I will go from the input to the longest line in two steps.
While I'm at it I also go ahead and throw in some labels on the arrows here.
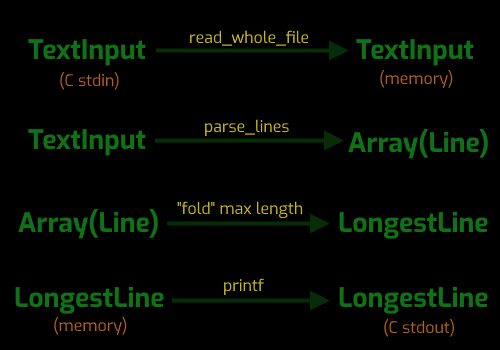
Notice that the third arrow isn't labeled with a function name but instead just a description. The name "fold" comes from that abstract world of functional programming and category theory. It describes the action that takes a collection, like an array of lines, to a single line, by applying some operator on an accumulator ranging over the collection. In other words that arrow isn't worth wrapping in a function of it's own, beacuse it is just a trivial for loop with an "accumulator" finding the longest line.
Also notice that the last arrow is labeled printf! This means I've found an opportunity to reuse an existing function for part of my solution.
Whenever there is an intermediate like "Array(Line)" in this diagram that we have invented ourselves, we're free to design the representation of that information however we like. This is where all those good data oriented design principles can come swinging. Is that an array of seperate strings copied from the input? Is it an array of pointers into the original input combined with length? How about just 32-bit indices giving the start of each line?
If we really wanted to optimize the information flow here, generating an array only to feed it into a fold and then never use it again is really beggin for those paths to be fused together. We could just scan for the pair of indices corresponding to the longest range between two newline characters.
Decomposing a "big" arrow into "smaller" arrows helps us find a design that will be easy to implement correctly. Then by selectively fusing arrows together we can design functions that may solve the problem more efficiently. By doing the first step we've checked that the composition works the way we expect first, and we've given ourselves an exemplar to test against for the more efficient version.
Let's compare this to the solution from the book, by looking at the information flow diagram that corresponds to that solution too:
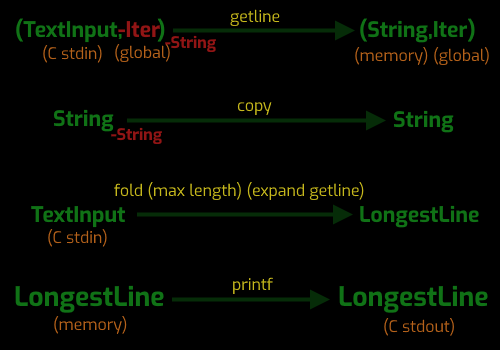
Now you might object that I have made the diagram look needlessly complex, but I don't think I have. If I want to capture everything that is important about what's going on here this is what I have to do. In fact I've failed to capture the fact that "copy" is part of composed "fold" thing. And I've left out some other quirks like the maximum length of the line, which I could have captured if I really wanted to be pedantic.
The rest of the details are too important to leave out. First the "getline" function, in it's C prototype has no "iter" parameter, or output, but that's because it is hidden as a global variable (via the position of the stdin stream). Whenever "getline" is called that global information is used to determine the output string, and the position of the stream is updated. So I need to show that some sort of iterator information is not only an input to this function, but actually destroyed by this function, and that new iterator information is produced by this function. On top of that this function has to destroy a string in memory. The destroyed string does not contain information that the function depends on, so it's annotated outside of the input parameters. Again, C hides information destruction in it's function signatures, but it's still important to be aware when information destruction is happening.
Because the function for extracting lines requires a string be destroyed, a copy function becomes necessary to preserve the longest string. This copy string also destroys a string without depending on the value of the string destroyed.
In my design the "fold" is relatively simple because it is just applied to an array that is constructed first. Here however I need to capture the fact that the "array" is virtually constructed by calling getline to expand the array on demand. In my design the arrow "parse_lines" isolates the code that extracts an array of lines from the fold, meaning we could explore all sorts of tricks for optimizing that path alone. Here the way the fold works is tangled up with the way the extractor works, which makes it harder to imagine options for optimization without total refactoring.
Now we have two designs, and I've analyzed them. Step three is to choose a design that is right for you. In this case there really isn't any constraint on me to guide a decision like this, but in a case like that there are a few "fall back" parameters I like to optimize. I prefer to choose a design that is easier to implement correctly, and I also prefer to choose a design that has the flexibility to be modified into other designs if constraints come along in the future. So I choose my design.
Step four implement.
#include <stdio.h>
#include <malloc.h>
typedef struct{
char *str;
int len;
} String;
String read_whole_file(FILE *file);
typedef struct{
/* contains one extra pointer to point at the end of the text */
char **line_ptr;
int count;
} LineArray;
LineArray parse_lines(String *text);
/* print longest input line */
main()
{
String text;
LineArray lines;
int i;
int longest_idx;
int longest_len;
text = read_whole_file(stdin);
lines = parse_lines(&text;);
longest_idx = -1;
longest_len = 0;
for (i = 0; i < lines.count; i += 1){
int len;
len = (lines.line_ptr[i + 1] - lines.line_ptr[i]);
if (len > longest_len){
longest_idx = i;
longest_len = len;
}
}
if (longest_idx != -1){
printf("%.*s", longest_len, lines.line_ptr[longest_idx]);
}
return(0);
}
String
read_whole_file(FILE *file){
String result;
fseek(file, 0, SEEK_END);
result.len = ftell(file);
fseek(file, 0, SEEK_SET);
result.str = (char*)malloc(result.len + 1);
fread(result.str, result.len, 1, file);
result.str[result.len] = 0;
return(result);
}
LineArray
parse_lines(String *text){
char *str, *opl;
int array_cap;
LineArray result;
str = text->str;
opl = str + text->len;
/* setup buffer (no arena so going with realloc stretchy buffer for now) */
array_cap = 100;
result.line_ptr = (char**)malloc(sizeof(char*)*array_cap);
/* emit first line */
result.line_ptr[0] = str;
result.count = 1;
for (; str < opl; str += 1){
if (*str == '\n' || str + 1 == opl){
if (result.count == array_cap){
array_cap *= 2;
result.line_ptr = (char**)realloc(result.line_ptr,
sizeof(char*)*array_cap);
}
result.line_ptr[result.count] = str + 1;
result.count += 1;
}
}
return(result);
}
So what are the strengths and weaknesses of this method? I will assert that it's absolute strongest point is that it allows you to analyze the quality of a design. You can see things like information dependence chains that are deeper than they need to be, duplicated code, poor isolation of external code, poor isolation of unreliable code, and so on. Compared to the narrative driven method, where the only way to figure out well designed everything is, is to finish it test it, and/or tweak the problem statement and see the design change, this is a huge step up.
This doesn't completely solve your problem if you don't know how to solve your problem, but with some practice in this method I find that it makes it easier to make incremental progress. Imagine you may not know how to find the longest line in a text file, but you would know how to find the longest string in an array, you can at least get started with that and then look at how your original problem reduces to that. This is a rather trivial case, but I've seen it work in much more complex cases too. Understanding the information relationships in the parts of the problem you do understand gives you ground to stand on to attack the parts you don't understand.
The final code does not read like a story of how the program solves the problem, but the final code does read like a sequence of data transformations composed together. Depending on your perspective maybe that's better, or maybe not.
The biggest weakness of this method is that it requires more practice to get used to it. In narrative driven methods you take the intuition you already have and just attack from there. In this method, you're asked to practice doing something a little more counter-intuitive first. Instead of just getting in there and getting it done, you're spending more time thinking about how your solution actually functions.
Another weakness of working this way is that it often creates first passes that have more total code - easier code - but more of it. Choosing these easier designs first can also be a strength when the time comes to test a very tricky highly optimized solution later.
Conclusion
That's more than enough for now. If you have any thoughts or questions about this reach out to me at allenw@mr4th.com. In future posts I'll give deeper examples of using this method to analyze patterns that appear in the solutions to various kinds of problems, to the architecture of large projects like 4coder. You can be notified of when these come out by subscribing to my Newsletter!